Fourier Head:
Fourier Head:
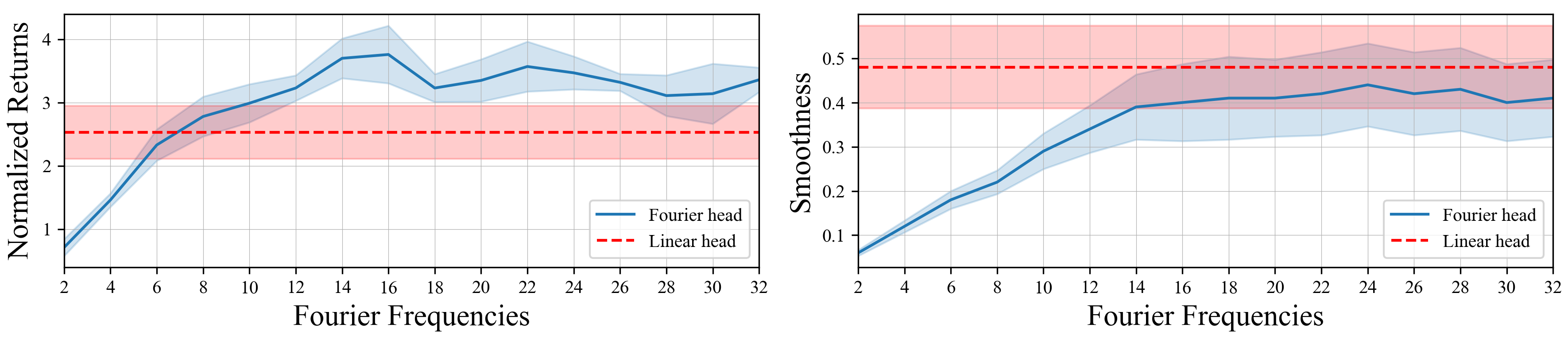
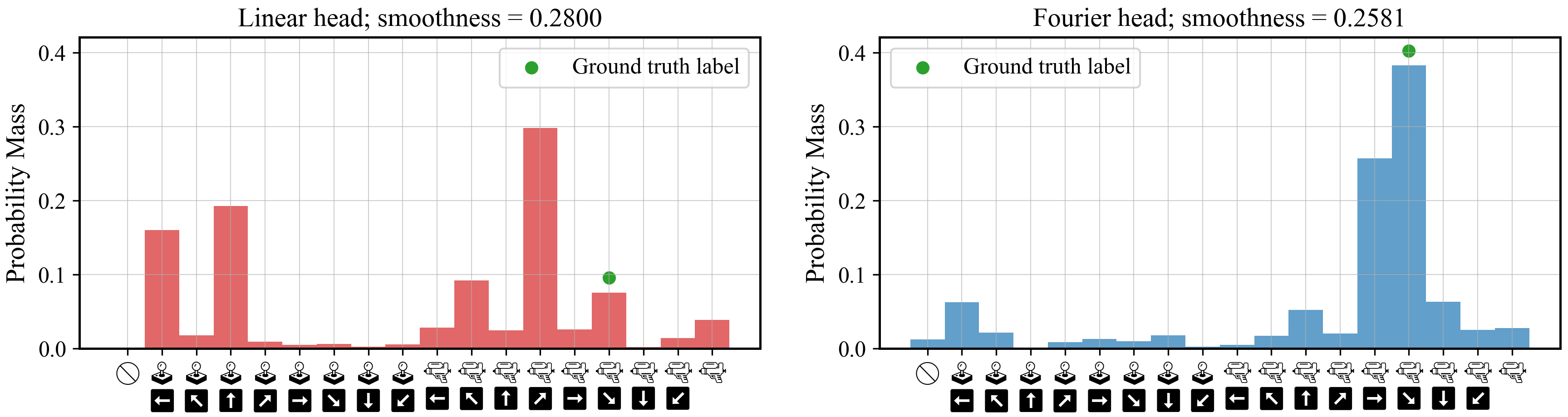
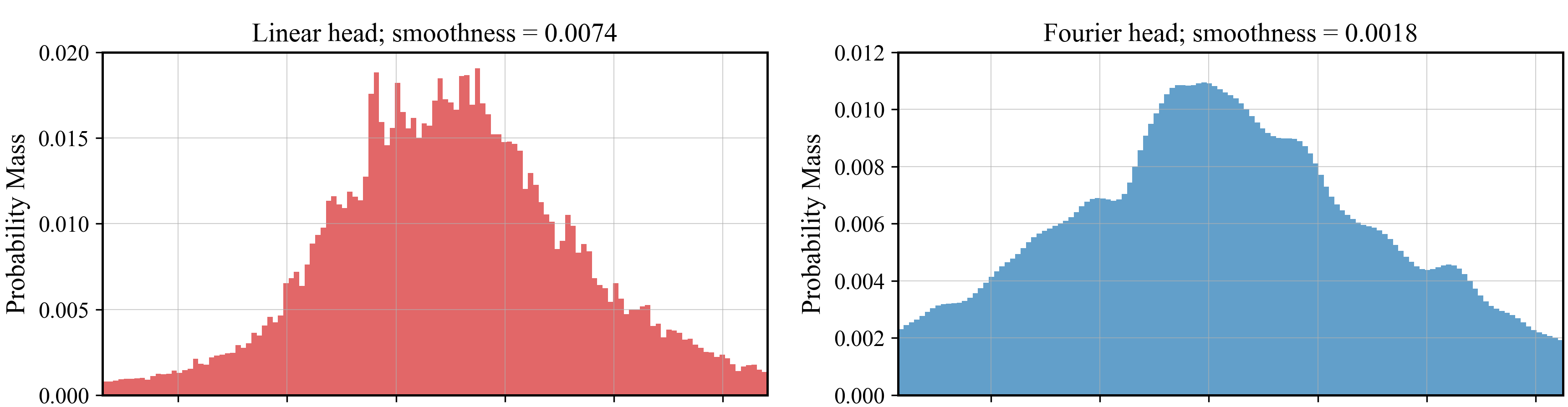
As the quality of large language models has improved, there has been increased interest in using them to model non-linguistic tokens. For example, the Decision Transformer recasts agentic decision making as a sequence modeling problem, using a decoder-only LLM to model the distribution over the discrete action space for an Atari agent. However, when adapting LLMs to non-linguistic domains, it remains unclear if softmax over discrete bins captures the continuous structure of the tokens and the potentially complex distributions needed for high quality token generation. We introduce a neural network layer, constructed using Fourier series, which we can easily substitute for any linear layer if we want the outputs to have a more continuous structure. We perform extensive analysis on synthetic datasets, as well as on large-scale decision making and time series forecasting tasks. We also provide theoretical evidence that this layer can better learn signal from data while ignoring high-frequency noise. All of our results support the effectiveness of our proposed Fourier head in scenarios where the underlying data distribution has a natural continuous structure. For example, the Fourier head improves a Decision Transformer agent's returns by 46% on the Atari Seaquest game, and increases a state-of-the-art times series foundation model's forecasting performance by 3.5% across 20 benchmarks unseen during training.
@inproceedings{
gillman2025fourier,
title={Fourier Head: Helping Large Language Models Learn Complex Probability Distributions},
author={Nate Gillman and Daksh Aggarwal and Michael Freeman and Chen Sun},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=4hPwLg7zD3}
}