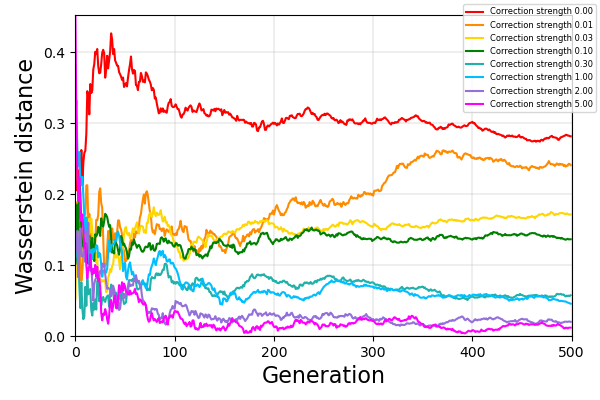
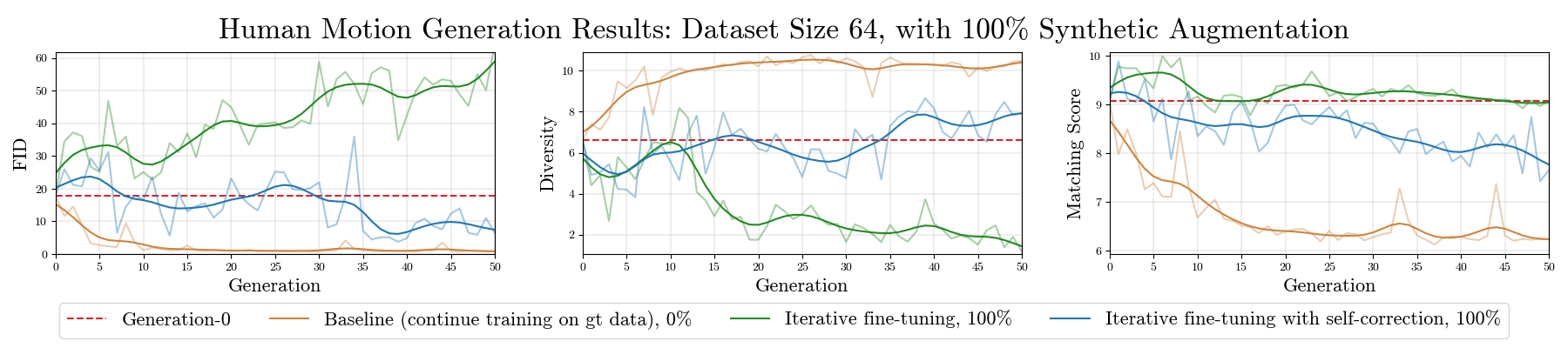
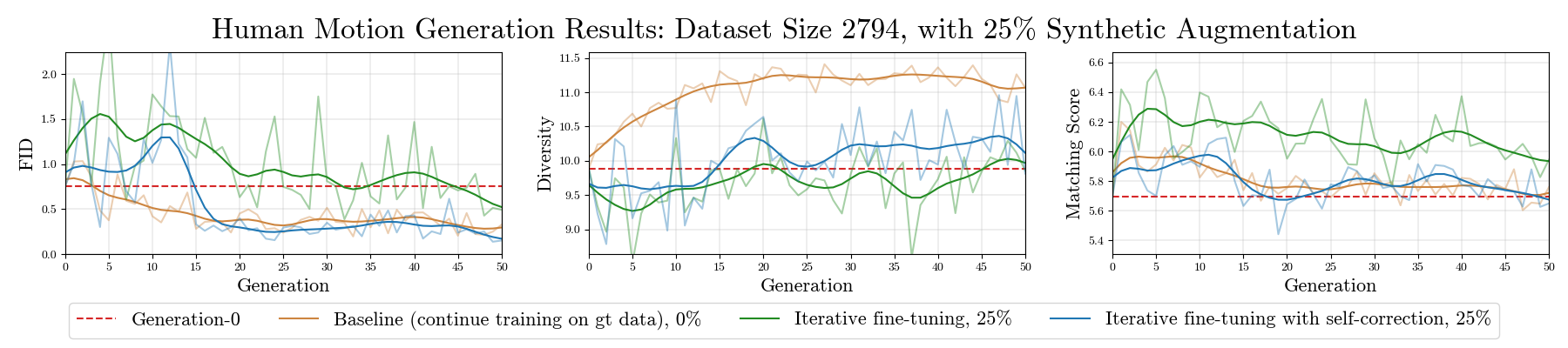
As synthetic data becomes higher quality and proliferates on the internet, machine learning models are increasingly trained on a mix of human- and machine-generated data. Despite the successful stories of using synthetic data for representation learning, using synthetic data for generative model training creates “self-consuming loops” which may lead to training instability or even collapse, unless certain conditions are met. Our paper aims to stabilize self-consuming generative model training. Our theoretical results demonstrate that by introducing an idealized correction function, which maps a data point to be more likely under the true data distribution, self-consuming loops can be made exponentially more stable. We then propose self-correction functions, which rely on expert knowledge (e.g. the laws of physics programmed in a simulator), and aim to approximate the idealized corrector automatically and at scale. We empirically validate the effectiveness of self-correcting self-consuming loops on the challenging human motion synthesis task, and observe that it successfully avoids model collapse, even when the ratio of synthetic data to real data is as high as 100%.
@InProceedings{gillman2024selfcorrecting,
title={Self-Correcting Self-Consuming Loops for Generative Model Training},
author={Gillman, Nate and Freeman, Michael and Aggarwal, Daksh and Hsu, Chia-Hong and Luo, Calvin and Tian, Yonglong and Sun, Chen},
booktitle={Proceedings of the 41st International Conference on Machine Learning},
pages={15646--15677},
year={2024},
volume={235},
publisher={PMLR}
}