 Howdy!! I'm a PhD student at Brown University,
where I'm fortunate to be advised by
Chen Sun.
I'm supported by Brown's
Department of Mathematics and
Department of Computer Science.
I study machine learning, computer vision, and artificial intelligence.
My current research focuses on video generative modeling and world modeling.
I like training deep generative models which approximate real-world physics.
In 2025 I interned at Google Research,
and in 2024 I interned at Amazon Science.
Howdy!! I'm a PhD student at Brown University,
where I'm fortunate to be advised by
Chen Sun.
I'm supported by Brown's
Department of Mathematics and
Department of Computer Science.
I study machine learning, computer vision, and artificial intelligence.
My current research focuses on video generative modeling and world modeling.
I like training deep generative models which approximate real-world physics.
In 2025 I interned at Google Research,
and in 2024 I interned at Amazon Science.
In the past I also did work in cryptography and pure mathematics, including number theory, algebraic geometry, and geometric measure theory. Fun fact: I actually started grad school as a PhD student in Brown's math department, conducting research in analytic number theory and cryptography with Jeff Hoffstein. I've since switched to AI, but I still like to make my background in pure math useful in my AI research. I completed my undergraduate degree at Wesleyan University. During my time in college I spent one semester at the Math in Moscow program and another at the Budapest Semesters in Mathematics program. My undergraduate math research advisor was Ken Ono, I spent two summers doing research with him at Emory University's Research Experience for Undergraduates.
I'm particularly inspired by the life of Walter Pitts, who proposed the first mathematical model of the neural network.
nate_gillman [at] brown.edu
Publications (AI/ML)
2026 Goal Force: Teaching Video Models To Accomplish Physics-Conditioned Goals
Goal Force: Teaching Video Models To Accomplish Physics-Conditioned GoalsNate Gillman, Yinghua Zhou, Zitian Tang, Evan Luo, Arjan Chakravarthy, Daksh Aggarwal, Michael Freeman, Charles Herrmann, and Chen Sun. CVPR 2026.
arXiv / Code / Project Page
 Force Prompting: Video Generation Models Can Learn and Generalize Physics-based Control Signals
Force Prompting: Video Generation Models Can Learn and Generalize Physics-based Control SignalsNate Gillman, Charles Herrmann*, Michael Freeman, Daksh Aggarwal, Evan Luo, Deqing Sun, and Chen Sun*. NeurIPS 2025.
arXiv / Code / Project Page
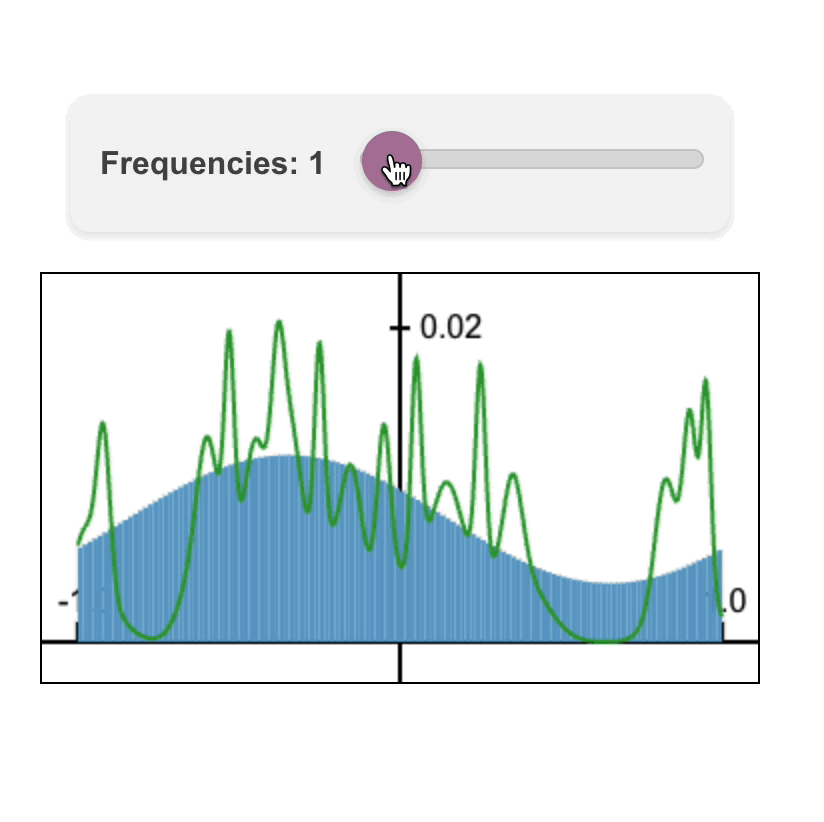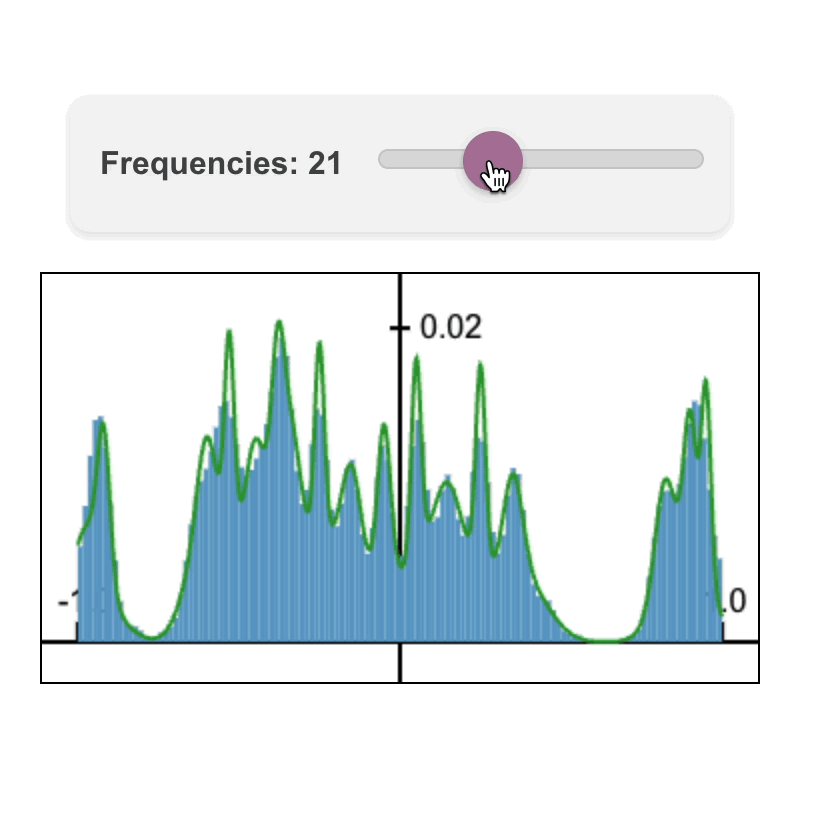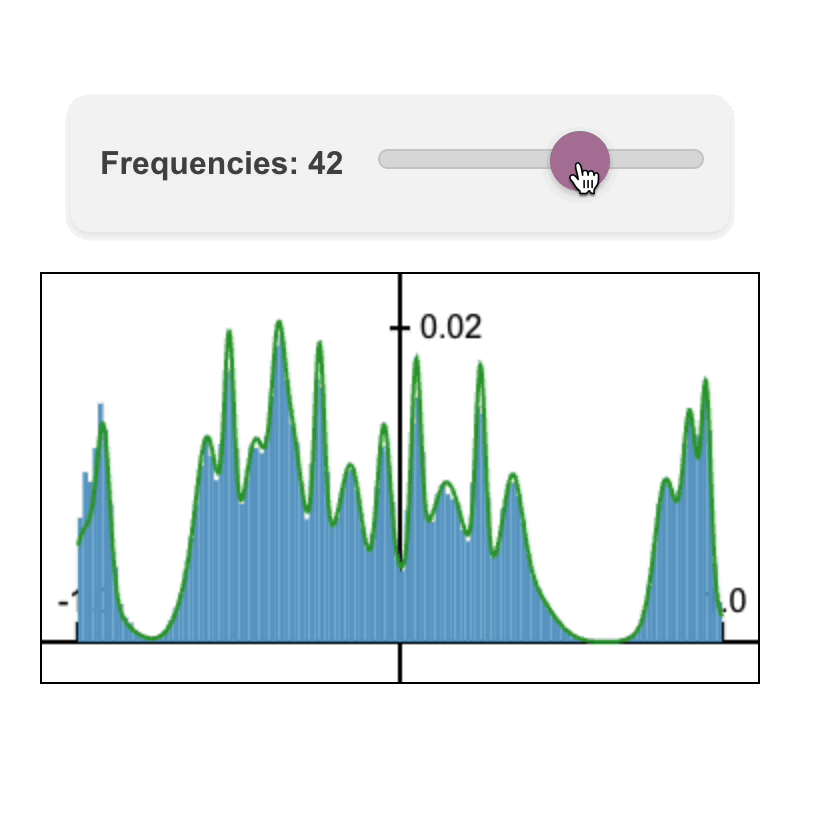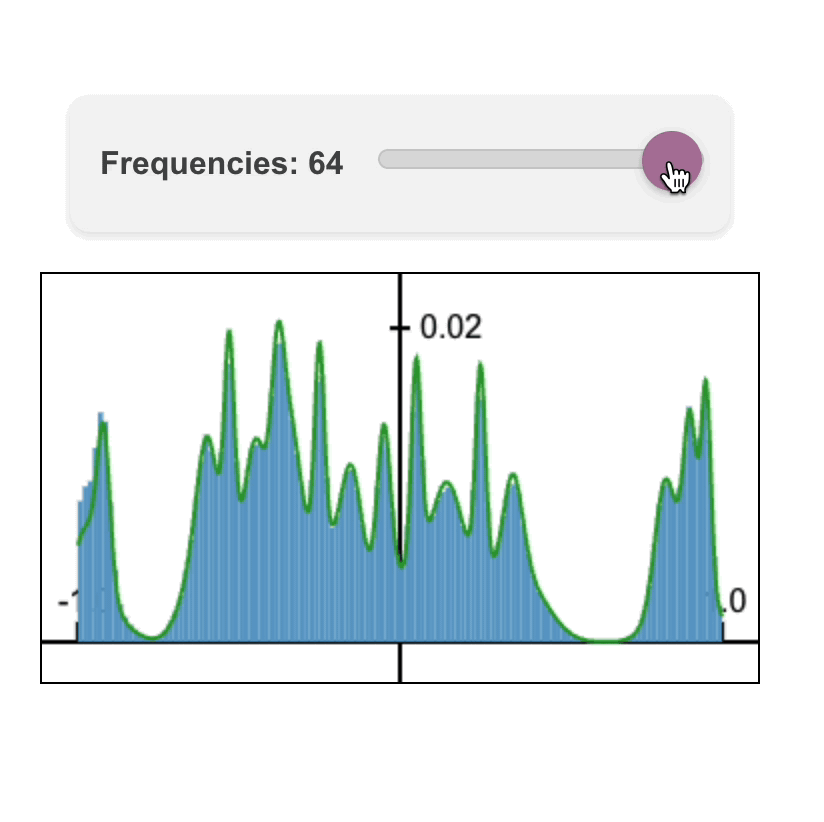
 Fourier Head: Helping Large Language Models Learn Complex Probability Distributions
Fourier Head: Helping Large Language Models Learn Complex Probability DistributionsNate Gillman*, Daksh Aggarwal*, Michael Freeman, Saurabh Singh, and Chen Sun. ICLR 2025.
arXiv / Code / Project Page
 Self-Correcting Self-Consuming Loops for Generative Model Training
Self-Correcting Self-Consuming Loops for Generative Model TrainingNate Gillman, Michael Freeman, Daksh Aggarwal, Chia-Hong Hsu, Calvin Luo, Yonglong Tian, and Chen Sun. ICML 2024.
arXiv / Code / Project Page / Conference
 IsoScore: Measuring the Uniformity of Embedding Space Utilization
IsoScore: Measuring the Uniformity of Embedding Space UtilizationWilliam Rudman, Nate Gillman, Taylor Rayne, and Carsten Eickhoff. ACL 2022.
arXiv / Code / Conference
Patents (AI/ML)
2022
Methods and systems for automatically generating and executing computer code using a natural language description of a data manipulation to be performed on a data set
Nate Gillman, Nadia Laflaf, Abraham Parangi, Jonathon Reilly, and Nathan Wies. U.S. Patent Application No. WO 2024/073098 A1. Filed Sep 29, 2023.
Nate Gillman, Nadia Laflaf, Abraham Parangi, Jonathon Reilly, and Nathan Wies. U.S. Patent Application No. WO 2024/073098 A1. Filed Sep 29, 2023.
Publications (Mathematics)
2021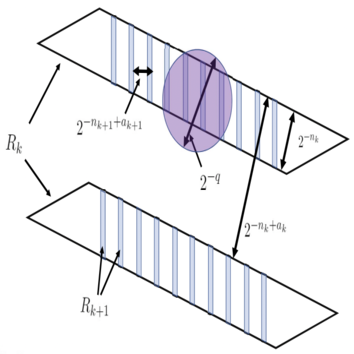 Large sets with small injective projections
Large sets with small injective projectionsFrank Coen, Nate Gillman, Tamás Keleti, Dylan King, and Jennifer Zhu (2021). Annales Fennici Mathematici, 46(2), 683-702.
arXiv / Journal
 Patterns of primes in the Sato-Tate conjecture
Patterns of primes in the Sato-Tate conjectureNate Gillman, Michael Kural, Alexandru Pascadi, Junyao Peng, and Ashwin Sah (2020). Research in Number Theory, 6(9).
arXiv / Journal / MathSciNet
 Explicit subconvexity savings for sup-norms of cusp forms on PGL(n,R)
Explicit subconvexity savings for sup-norms of cusp forms on PGL(n,R)Nate Gillman (2020). Journal of Number Theory, 206, 46-61.
arXiv / Journal / MathSciNet
 From partitions to Hodge numbers of Hilbert schemes of surfaces
From partitions to Hodge numbers of Hilbert schemes of surfacesNate Gillman, Xavier Gonzalez, Ken Ono, Larry Rolen, and Matthew Schoenbauer (2019). Philosophical Transactions of the Royal Society A, 378: 20180435.
arXiv / Journal / MathSciNet
 Exact formulas for invariants of Hilbert schemes
Exact formulas for invariants of Hilbert schemesNate Gillman, Xavier Gonzalez, and Matthew Schoenbauer (2018). Research in Number Theory 4(39).
arXiv / Journal / MathSciNet